
Via ett tips från Gino Almondo fick jag kännedom om uppsatsen A Framework for Understanding Sources of Harm through the Machine Learning Life Cycle (Suresh & Guttag, 2021). Den innehåller ett mycket användbart diagram som beskriver var och hur bias kommer att påverka resultatet av maskininlärningsprocessen. Jag kunde inte låta bli att tillämpa mitt eget bildspråk för användning i min undervisning. Använd gärna dagrammet för att förstå varför och hur så kallade "AI"-verktyg kan, och ofta kommer, att bidra till skada.
Detta är en översättning av mitt engelska inlägg från september 2023.
Jag kontaktade författarna, Harini Suresh och John Guttag, och har fått deras tillåtelse för min omformning av deras diagram. För en djupgående förståelse av de olika fördomarna rekommenderar jag att du dyker ner i deras uppsats. Här följer en kort översikt över vad diagrammet belyser.
Översikt över bias i maskininlärning
Inget system är starkare än sin svagaste länk. Suresh & Guttag förklarar i sin uppsats var de svaga länkarna i maskininlärning finns, och inkluderar både processen för datagenerering samt processen för modellbyggande och implementering.
a) Datagenerering
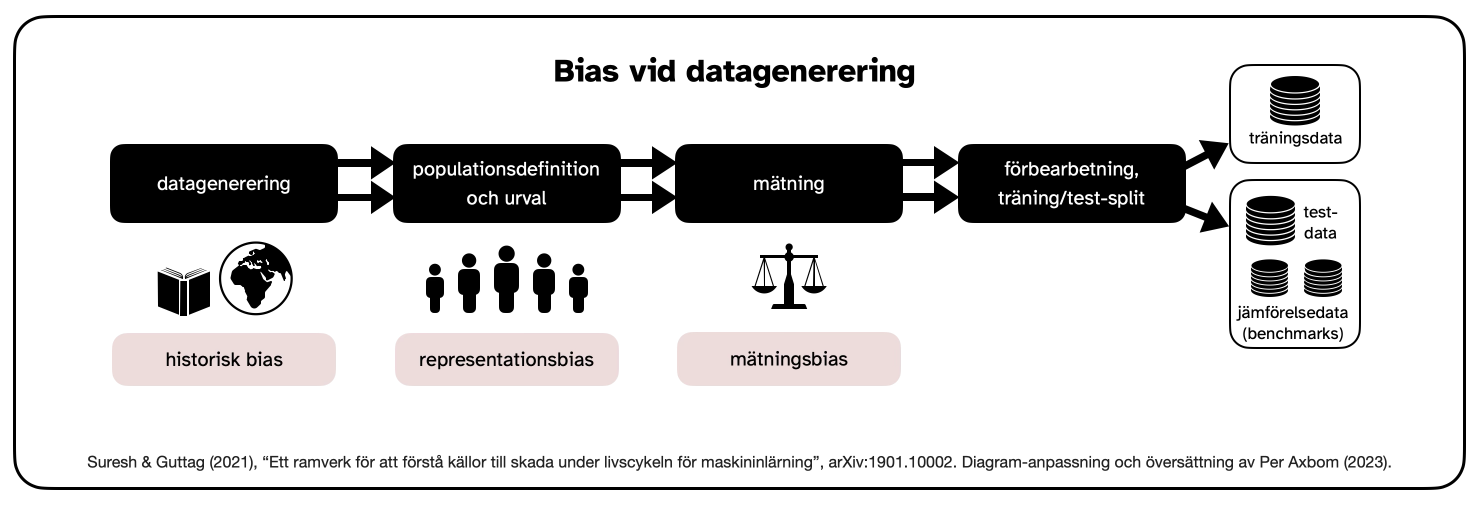
Punkterna där bias uppstår är:
- Historisk bias. Skadliga resultat uppstår när människor felbehandlas på grund av fördomar som finns i dataunderlaget. Observera att skada kan och kommer att hända även om dataunderlaget ger en fullständigt korrekt representation av världen. Detta beror på att verkliga fördomar, både aktuella och historiska, blir inbäddade i programvara som fungerar snabbare (i huvudsak accelererar fördomar), når längre och är svårare att avslöja och invända mot.
- Representationsbias. När betydande delar av befolkningen inte finns representerade i dataunderlaget kan verktyget misslyckas med att generalisera på ett bra sätt för den population som den används av eller för. Målpopulationen i dataunderlaget kanske inte representerar populationen som använder verktyget, eller så kan det innehålla underrepresenterade grupper – där det finns mindre data att lära av. Provtagningsmetoden kan också vara begränsad eller ojämn Exempel: om hälsodata för ett ovanligt tillstånd är nindre tillgängligt, eller om det är sällan undersökt, kommer det leda till sämre prestanda för det hälsotillståndet.
- Mätningbias. När modellerna används för att förutsäga och "förstå" behöver de urval, insamling och beräkning av egenskaper och etiketter att dra slutsatser från. Dessa etiketter kan vara alltför förenklade, eller så kan metoden/noggrannheten variera mellan grupper. Exempel: kreditvärdighet baserad på någon form av poängsättning, eller data som visar höga brottsfrekvenser baserat på att det finns mer brottsbekämpande närvaro i området – det leder till mer upptäckta fall och än mer närvaro. Något så enkelt som bedömning av smärta kan också variera mellan grupper.
b) Modellbyggande och implementering
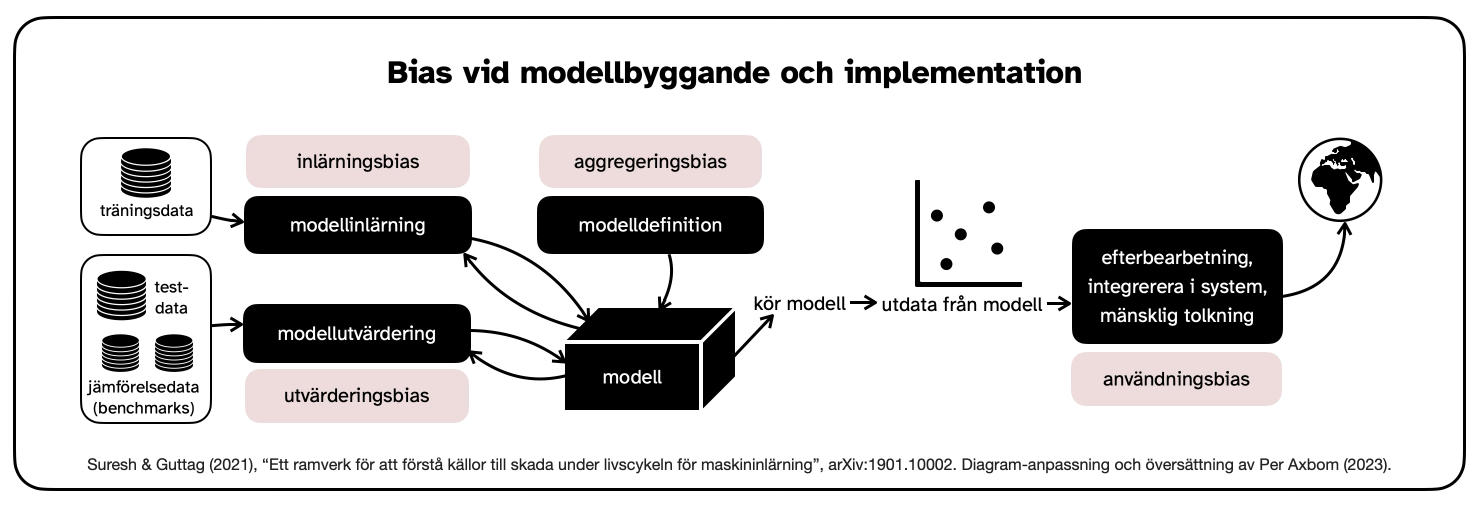
Punkterna där bias uppstår är:
- Utvärderingsbias. En modell är optimerad på sina träningsdata, men dess kvalitet mäts ofta på benchmarks, eller jämförelsedata. Därför bidrar ett missvisande underlag i denna jämförelsedata till utvecklingen och användningen av modeller som bara fungerar bra på den delmängd av data som representeras av jämförelsedatan. Detta underlag kan i sig lida av historisk, representations- eller mätningsbias. Exempel: bilder av mörkhyade kvinnor utgör endast 7,4 % och 4,4 % av två populära benchmark-underlag: Adience och IJB-A. Därför misslyckas benchmarking (ungefär: jämförelsetester) med dessa underlag att upptäcka när modellen underpresterar för denna del av befolkningen. (Buolamwini och Gebru, 2018.)
- Inlärningsbias. Skillnader i prestanda uppstår för olika typer av data på grund av modelleringsbeslut som tas för att påverka till exempel noggrannhet eller objektivitet. Dessa beslut kan urholka inflytandet från underrepresenterade data, och därefter presterar modellerna ännu sämre på den datan.
- Aggregeringsbias. En viss datauppsättning kan representera människor eller grupper med olika bakgrunder, kulturer eller normer, och varje given variabel kan indikera olika saker i dessa grupper. En modell som passar alla kan misslyckas med att optimera för någon grupp eller bara passa den dominerande befolkningen Exempel: modeller som används i anställningsprocesser för analyser av känslor kan misslyckas med att beakta skillnader i ansiktsuttryck som kan relatera till kultur eller vissa funktionsnedsättningar.
- Implementeringsbias. Vissa modeller kan komma att användas på ett sätt som de inte var avsedda att användas. Som Guttag & Suresh skriver: "Detta inträffar ofta när ett system byggs och utvärderas som om det vore helt autonomt, medan det i verkligheten fungerar i ett komplicerat sociotekniskt system som modereras av institutionella strukturer och mänskliga beslutsfattare." Detta är också känt som "framing trap" (Selbst et al., 2019). Dessa verktyg kan leda till skada på grund av automatisering eller bekräftelsebias. Exempel: felaktiga råd från ett AI-baserat beslutsstödssystem kan försämra radiologers bedömningsförmåga när de tittar på röntgenbilder inom mammografi.
Så kan du använda diagrammet
När du bygger, bedömer och utvärderar system baserade på maskininlärning är en del av ditt ansvar att förstå på vilka sätt verktyget kan bidra till skada. Var transparent med dessa frågor och visa att påtaglig, djupgående analys krävs för att problemen ska kunna avslöjas och hanteras.
Ibland blir svaret att ett verktyg baserat på maskininlärning inte är rätt verktyg för jobbet. Detta måste man förstå tidigt, innan människor kommer till skada.
Referenser
- Axbom, Per (2023). Förklaringsmodell för ansvar, påverkan och makt inom AI. axbom.se, 11 december.
- Axbom, Per (2023). Om en hammare var som AI. axbom.se, 27 september.
- Axbom, Per (2023). Elementen inom AI-etik. axbom.se, 19 juni.
- Axbom, Per (2022). Elementen inom digital etik. axbom.se, 4 april.
- Buolamwini, J., Gebru, T. (2018). Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification., Proceedings of Machine Learning Research 81:1–15, 2018 Conference on Fairness, Accountability, and Transparency
- Buschek, Christo & Thorp, Jer (2024). Models all the way down, knowingmachines.org
- Dratsch, Thomas et al (2023). Automation Bias in Mammography: The Impact of Artificial Intelligence BI-RADS Suggestions on Reader Performance, RadiologyVol. 307, No. 4
- Selbst, Boyd et. al (2018). Fairness and Abstraction in Sociotechnical Systems, 2019 ACM Conference on Fairness, Accountability, and Transparency (FAT*)
- Suresh, Harini; Guttag, John (2021). A Framework for Understanding Sources of Harm throughout the Machine Learning Life Cycle, MIT Open Access Articles.
- Winner, Langdon (1980). Do Artifacts Have Politics?, In Daedalus, Vol. 109, No. 1, Modern Technology: Problem or Opportunity?





Medlemsdiskussion