
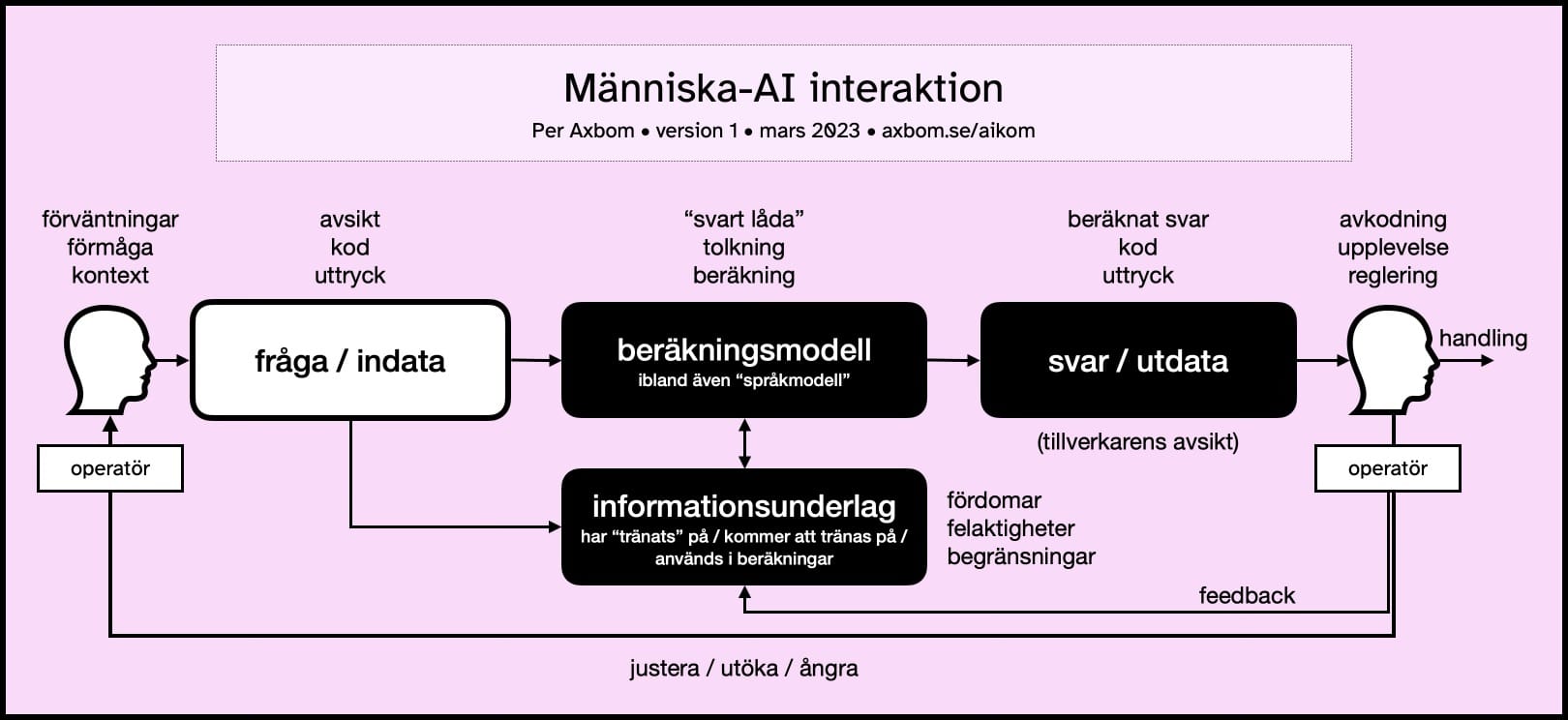
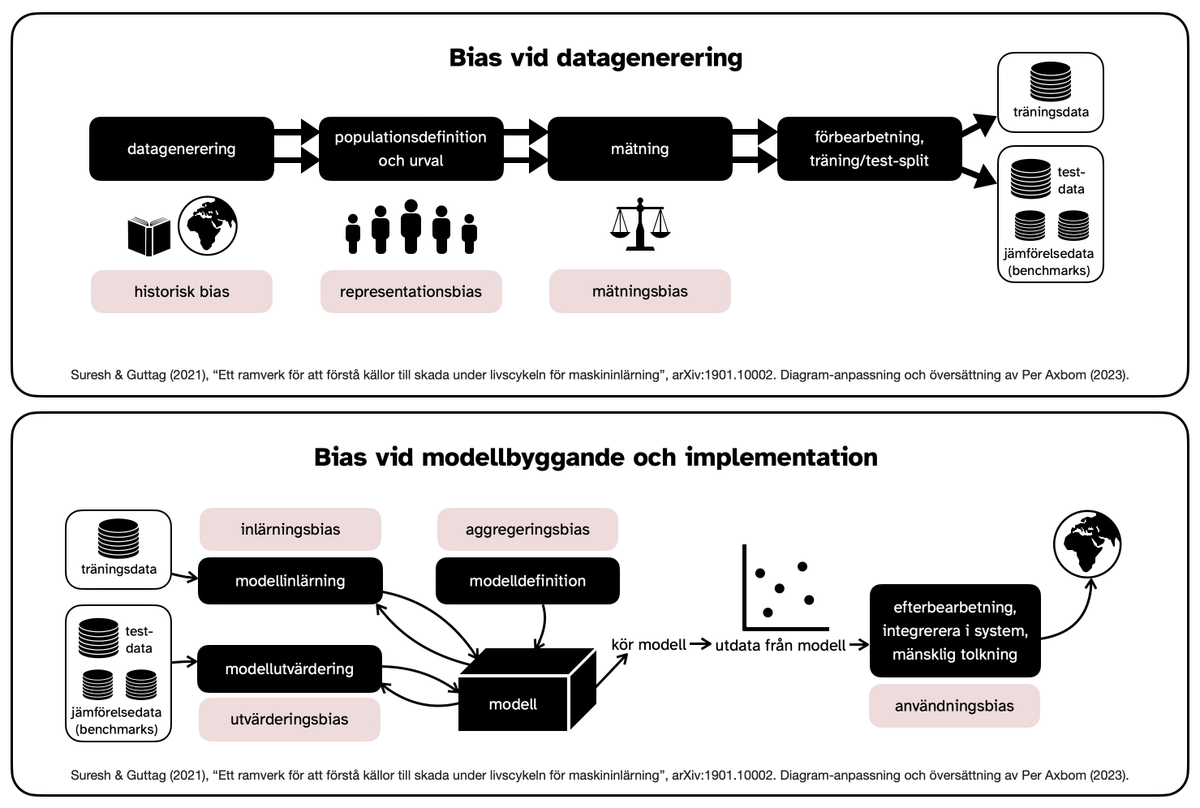
Som underlag för arbete med att utveckla, underhålla och förbättra AI-baserade tjänster har jag ritat en ny kommunikationsmodell. Notera att fokus här är på människans interaktion med digitala verktyg som till viss del förlitar sig på maskininlärning. Det handlar om de beståndsdelar som påverkar indata (från människan) och utdata (från datorn), och i förlängningen vad en människa gör baserat på utdatan. Således utgör det människa-AI interaktion (MAII), ett kommunikativt lager ovanpå människa-dator interaktion (MDI).
Diagrammet bidrar med ett kommunikationsvetenskapligt perspektiv för att bättre förstå när, var och hur i användning och tillämpning av dessa AI-verktyg som man kan göra en insats för att förbättra till exempel
- begriplighet,
- tillfredställelse och
- nytta.
Kommunikationsmodellen används till fördel inom införandeplanering, designbeslut, kommunikativa insatser och utbildning.
Skapad: 2023-03-07
Ändringar: Namnet på modellen ändrades 2025-05-08. Det tidigare namnet var Kommunikationsmodell för AI-verktyg med operatör.
Licens: CC BY-SA
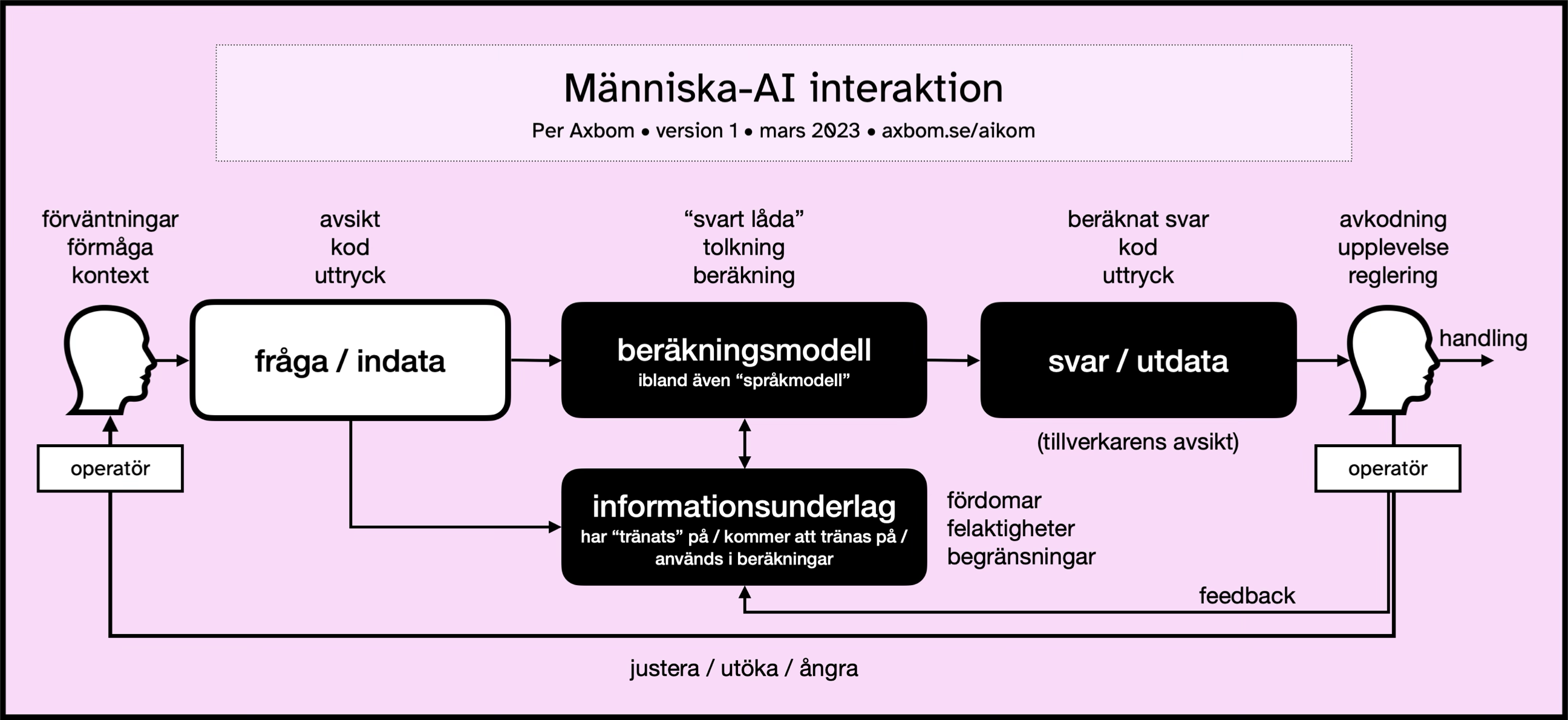
Här följer en sammanfattning av de olika beståndsdelarna. Jag börjar till vänster i modellen, med en operatör som vill åstadkomma något. Operatör används här för att beskriva en människa som styr en interaktion med en maskin.
Även om många exempel utgår ifrån språkmodeller (large language models) fungerar den här kommunikationsmodellen för alla system där en människa ställer en fråga, eller ger en instruktion, till en beräkningsmodell.
Operatörens mänsklighet
När en människa ska interagera med en dator så behöver vi ha i åtanke flera aspekter av människans omständigheter:
- Förväntningar. Hur har personens förväntningar formats och hur väl stämmer de med vad som är möjligt i situationen? Hur kan vi hjälpa till så att dessa förväntningar ligger på en bra nivå? Och hur avgör vi vad som är en bra nivå?
- Förmåga. Givet personens erfarenheter, kunskaper samt fysiska och kognitiva kapacitet, hur väl rustad är personen för att interagera med datorn – till exempel när det gäller att formulera sig på ett sätt som gör att datorn ger ett resultat man är nöjd med och inte vilseleder. Hur ser vi till att anpassa verktyget till operatörens förmåga?
- Kontext. I vilket sammanhang befinner sig personen och hur kan det till exempel påverka deras möjligheter att agera som de själva skulle önska. Hur arbetar vi med att förstå kontext och ta hänsyn till detta?
Inmatning av fråga, eller indata
När människan ska skriva in sin frågeställning eller uppmaning så görs det ofta på ett sätt som lämnar utrymme för tolkning.
- Avsikt. Har personen en avsikt som vi i efterhand kan kontrollera och verifiera. Hur hjälper vi operatören att formulera sin avsikt?
- Kod. Kan personen koda sin avsikt, språkligt, på ett sätt som gör att det till exempel blir otvetydigt eller användbart för beräkningsmodellen på ett sätt som minimerar tvetydighet. Vilket stöd kan bidra till att kodningen av frågan blir mer exakt?
- Uttryck. Innehåller indatan en uttrycksform som kan påverka beräkningsmodellen i någon riktning. Det kan till exempel handla om formellt, ledigt eller barnsligt språk. Hur tillåtande eller vägledande bör verktyget vara kring dessa uttryck?
Beräkningsmodellen startar sin process
I själv modellen som ska ta människans indata händer förstås massor av saker . Några av de viktigaste aspekterna att ha i åtanke är:
- "Svart låda". Det är dolt för människan hur det här fungerar. Väldigt mycket lämnas till fantasi och förväntningar som byggs upp av yttre omständigheter. Även om det skulle vara så att den modell som används släpps som ”öppen” (vilket i sig kan vara en vilseledande beskrivning) så har de flesta människor inte förmågan att förstå hur beräkningsmodellen fungerar. Ofta finns heller inte någon insyn i vilket innehåll som använts för att skapa modellen, eller om det finns oetiska dimensioner i val innehåll och insamlingen av innehåll. Man får bygga en egen berättelse i huvudet för att hantera ovissheten. Vilka berättelser kan hjälpa och vilka vilseleder i onödan?
- Tolkning. Det sker en maskinell tolkning av människans formulering men inte på det sätt som en människa tolkar någon annan. Om det handlar om en språkmodell så används generellt någon form av statistisk analys för att helt enkelt räkna fram vad som är de mest sannolika orden och meningarna som passar med det som människan matat in. Detta är baserat på den data som använts för att "träna" modellen. Hur trygga är vi med tolkningen för det syfte vi vill använda verktyget till?
- Beräkning (framför sanning). En beräkning av de mest sannolika meningarna innebär bland annat att även om modellen har "tränats" på, och endast matats med, rena faktatexter så kommer den att hitta kombinationer av meningar som är sannolika men inte nödvändigtvis sanna. Det sker ingen aktiv check för att öka sanningshalten i beräkningen, och sanning är inget som kan avgöras av modellen på egen hand. AI-modellen är ett datorprogram som följer instruktioner. Har vi ordentlig koll på vad beräkningen faktiskt gör så att vi inte lovar sådant den inte gör?
Ett sätt att beskriva detta på är att språkmodeller ofta optimeras för att svaren ska upplevas som sanna, men inte att de ska vara sanna. Det är en språkmodell, inte en kunskapsmodell. Företagen vill gärna att svaren också ska upplevas som att de är skrivna av en människa... men det vet vi ju redan inte alls är sant.
Hänsyn till informationsunderlag
Det talas ofta om den information som beräkningsmodellen "tränats" på. I kommunikationsmodellen finns detta noterat i rutan informationsunderlag, som också inbegriper annan information som potentiellt kan bidra till beräkningsmodellen.
När man hör berättelser om ChatGPT och liknande verktyg kan det ibland låta som att verktyget har tillgång till hela Internet som informationskälla när den ska ge svar. Men så är det förstås inte. Det går inte att komprimera allt innehåll på internet i en databas och låta en beräkningsmodell ställa frågor till databasen. Det finns som regel ingen sådan databas att tillgå. Däremot kan verktyget ha tränats på stora mängder innehåll som hittats på internet, med eller utan samtycke, Ofta utan.
AI-verktyget har matats med dessa texter för att beräkningsmodellen ska få mer underlag för att justera hur beräkningar ska ske, och i bästa fall blir mer tillförlitliga, i alla fall rent statistiskt. När det gäller en språkmodell är det alltså dessa beräkningar som väljer ut ord så att verktyget efterliknar texter skrivna av en människa. Att "tränas" med stora mängder information kan göra beräkningsmodellen mer tillförlitlig när det gäller att imitera mänsklig konversation och mänskligt skrivande, men har sällan att göra med mer sanningsenlighet.
Begreppet Large Language Models (LLM) kommer sig utav att mängden information de tränats med är just väldigt stor (large). Idén är att ju större informationsmängd man använt sig av, desto "bättre" förutsägelser kommer språkmodellen göra när den ska avgöra vilken text, eller utdata från modellen, som matchar frågan, eller indatan. Alltså att det blir trovärdigt alldeles oaktat riktighet.
På samma sätt kan vi se att verktyg som genererar konst kan göra det på ett sätt som blir mer trovärdigt för människor ju fler konstverk och visuella artefakt skapade av människor som beräkningsmodellen tränas med. Samtidigt som vi vet att den konst som genereras, även för det som ser ut som foton, aldrig avbildats på riktigt. Trovärdigheten i utdatan, och maskinens fömåga att imitera, skapar stora utmaningar i att hjälpa människar förstå att texten och bilder inte har med verkligheten att göra. Bara mänsklig avläsning och tolkning kan skapa mening.
Exempel på ett område där språkmodeller gör tydlig nytta är taligenkänning. Det är ett område som funnits och förfinats länge, men endast börjas beskrivas som ”AI” under senare år.
Vissa ord eller begrepp uttalas olika av olika personer, eller kan sammanblandas med bakgrundsljud. En språkmodell kan då hjälpa till att avgöra sannolikheten för att det är vissa ord som sägs, baserat på alla ord som sägs runtomkring och allt det informationsunderlag den tränats på. Det språkmodellen har som syfte i detta fall är att helt kopiera det människan säger och transformera det till text. Det blir väldigt tydligt vad människans avsikt är, och det går direkt att verifiera om resultatet stämmer med såväl kod (språk) som förväntningar.
Annat är det med språkmodeller där målet är konversation, eller där målet inte är särskilt tydligt definierat. Då kan alla möjliga typer av problem uppstå.
Följande parametrar innebär inte alltid fel, men kan vara relevanta beroende på vilket syfte en beräkningsmodell har. När man förstår hur oerhört mycket information som en modell matas med inser man nämligen också att de människor som tillverkar modellen självklart inte har möjlighet att själva läsa innehållet och på något sätt värdera dess relevans. I branschen kallas det för oövervakad inlärning.
- Fördomar. Texterna som blir lästa kan innehålla oerhört mycket fördomar av olika slag, inklusive extrema åsikter och hets mot folkgrupp. Det handlar inte bara om uppenbar rasism utan också mer subtila inferenser om att män till exempel förtjänar mer lön än kvinnor. Faktum är att givet den stora mängden innehåll som AI-verktyg går igenom så kan dessa skeva åsikter fångas upp av material som många människor vid första anblick skulle bedöma som neutralt.
Eftersom det behövs mycket material för att en modell ska bli "bättre", så innebär det alltid att det är väldigt mycket historiskt material som används, där det naturligtvis finns fördomar. Värderingar förändras över tid men i gammalt material är de låsta. - Felaktigher. Direkta faktafel finns förstås också i materialet som blir inläst. Men det är viktigt att komma ihåg att det inte är primärt detta som gör att språkmodeller så ofta kan ge fel svar. Fel svar ges för att modellerna inte har som syfte att generera fakta, utan har som syfte att imitera människors språk. Men precis som att en platt världskarta kan bidra till en skev bild av hur vår planet ser ut, så kan felaktigheter som uttrycks som sanningar i decennier bidra till att dessa lyser igenom i statistiska beräkningar.
Till exempel har konstformer med ursprung i det som idag är Nigeria länge i europeiskt skriftspråk tillskrivits grekiskt ursprung. Det är i sig fördomar som leder till antaganden som leder till felaktigheter som uttrycks som sanning. Många sådana mönster, till exempel en historisk ovilja att namnge afrikanska konstnärer, kan leda till att en språkmodell inte kan hitta statistiskt säkerställda sätt att beskriva konst och annan kultur med afrikanskt ursprung. Det finns långt fler texter som pekar ut Yorubanska metallskulpturer som grekiska, även om man på senare år har förstått bättre och anger rätt ursprung. Så rent statistiskt - om man tittar på mängden texter - så är den grekisk. - Begränsningar. Vi vet ju att det inte är hela Internet som används som informationsunderlag. Begränsningar görs. Någon väljer ut informationskällor. Någon väljer ut språk. Någon väljer ut tidsperioder för underlaget, eftersom det måste börja och sluta någonstans. Och alla dessa begränsningar skapar förstås sina egna skevheter eftersom man aldrig kan påstå att underlaget är vare sig representativt eller neutralt.
Idag finns mer än 7.000 språk och dialekter i världen. Endast cirka 7% av dessa finns återspeglade i material online. Cirka 98% av webbsidor på nätet publiceras på endast 12 språk, och mer än hälften av dessa är på engelska.
Cirka 76% av internetanvändare bor i Afrika, Asien, Mellanöstern, Latinamerika och Karibien – men större delen av innehåll kommer någon annanstans ifrån. På Wikipedia kommer till exempel mer än 80% av innehållet från Europa och Nordamerika.
Resultatet av svagheter i informationsunderlaget kan alltså innebära att man suddar ut hela regioner, kulturer och språk från representation i möjliga svar.
När man använder AI-verktyg måste man uppmärksamma alla svagheter och hur gamla värderingar kan förstärkas av dem.
Svaret presenteras
Efter genomförd beräkning så presenteras svaret för operatören. Det är viktigt att komma ihåg nu att även här tas väldigt många viktiga beslut av tillverkaren. Det finns inte bara ett sätt att presentera svar på utan förstås oändligt många sätt. Det gäller att försöka utröna tillverkarens avsikt med det sätt som har valts.
- Beräknat svar. Får vi någon ledtråd till varför utdatan ser ut som den gör och hur själva frågan påverkade utdatan? För den som vill förstå inte bara svaret, utan också skälet till svaret, finns förstås här möjlighet att ge till exempel information om hur väl svaret passar den statististiska modellen, eller be om mer information för att komplettera och förbättra. Förvånansvärt sällan ser vi den formen av transparens och stöd. Det är förstås också en typ av information som påminner om att det är en maskin vi har att göra med, och om man vill tona ner det det så vill man också dölja allt som indikerar det. Ibland talas om att människor och AI ska samarbeta för bästa resultat, och det finns designbeslut att ta här som kan påverka vad som menas med samarbete. Vilka delar i beräkningen är relevanta för operatören att känna till?
- Kod. Återigen ska även svaret, eller utdatan, presenteras på ett sätt som är lätt att ta till sig men som också matchar indatan och syftet med verktyget. I bästa fall kan vi verifiera att utdatan är rimlig och relevant utifrån indatan. Svagheten är att ett oerhört välformulerat svar (en övertygande människo-imitation) kan i sig bidra till att man inte lika lätt ifrågasätter svarets giltighet. Om det dessutom saknas visuella signaler om hur svaret är uträknat så finns än färre incitament att ifrågasätta. Hur kan koden anpassas för att operatörens tolkning ska bli relevant och användbar?
- Uttryck. På samma sätt som människan kan skriva på ett särskilt manér så kan också utdatan matcha det. Här kan tillverkaren välja att matcha indatan, följa givna instruktioner eller hitta en helt egen tonalitet. Microsofts senaste AI-verktyg fick kritik för att lägga till väldigt mycket emoji-symboler i sina svar. Det är förstås tillverkarens beslut att uttrycket såg ut på det sättet, och det ger ett bra exempel på hur uttryck är en stor del av hur svaret tas emot. Vilken nivå av eget uttryck är lämpligt givet verktygets användningsområde?
Hantera svaret
Operatören som nu får svaret till sig måste själv avgöra dess relevans och trovärdighet.
- Avkodning. Att kunna läsa svaret och förstå alla dess beståndsdelar kräver förstås att svaret avslöjar allt detta. Kom ihåg: avkodningen handlar inte bara om att till exempel kunna läsa och förstå texten i ett givet svar. Det handlar också om att bilda sig en uppfattning om hur svaret ger värde utifrån frågan, eller om det inte alls lever upp till förväntan. Det finns en balansgång mellan att förenkla och att erbjuda allt. Vilket stöd kan erbjudas när operatören avkodar för att bättre förstå vad som är tveksamt och vad som är definitivt i utdatan?
- Upplevelse. Det man känner och förnimmer som en effekt av hur svaret ser ut och presenteras spelar också roll för förtroende och nöjdhet. När avkodningen i till exempel överträffar förväntan i sitt uttryck, eller leder till nya tankar och idéer, kan förtroende och nöjdhet gynnas även när svaret inte har en direkt korrelation till den avsikt som fanns när frågan ställdes. Förstår vi helheten i upplevelsen på ett sätt så att vi också förstår varför operatören reagerar och agerar som hen gör?
- Reglering. Givet hur nöjd eller missnöjd operatören är med svaret kan det finnas skäl att bjuda in till olika sätt att gå vidare som innebär att man stannar kvar i verktyget men nu reglerar den genomförda interaktionen för att styra mot ett annat svar. I modellen ser vi till exempel justera, utöka och ångra som exempel på hur operatören fortsätter genom att reglera hela, eller delar av, frågan. En del verktyg uppmuntrar också till återkoppling genom att fråga om man är nöjd eller missnöjd med svaret. Det här kan innebära en feedback-mekanism som i något läge används för att påverka beräkningsmodellen. På vilka sätt kan operatören hjälpa sig själv, andra eller verktyget till en högre grad av användbarhet med utgångspunkt i ett redan givet svar?
Handling och följdeffekter
Handlingen innebär nu att ta svaret och använda det för en tillämpning i något helt annat sammanhang. Vi måste därför tänka ytterligare ett steg, utanför kommunikationsmodellen.
- Hur används svaret för att skapa nytta?
- Hur kan vi bättre bidra till ett format, och integrationer, som gör svaret användbart i nästa led av anvädning?
- Vem äger svaret?
- Hur kan svaret hjälpa?
- Hur kan svaret skada?
Frågorna som ställs här kommer behöva arbetas fram i undersökningar och intervjuer, men också med målinriktad framsynthet. Vi måste våga ställa de svåra frågorna och föreställa oss såväl de önskade som oönskade framtidsscenarierna för att kunna bidra till lämpliga åtgärder som förslagsvis minimerar risker och gör dem synliga när det behövs.
För att kunna göra detta på ett bra sätt måste vi ha en tydlig intention och avsedd användning för AI-baserade verktyg i våra verksamheter.
Om vi satsar på att använda och integrera AI-verktyg i en verksamhet och ingen tar ansvar för effekten på människor, eller för att definiera och värdera nytta, så har vi gett upp innan vi har börjat. Då blir strategin att vänta tills något går snett och att släcka bränder utan förebyggande arbete eller planerad hantering.
Den här kommunikationsmodellen finns som stöd när du aktivt vill arbeta för att åstadkomma genomtänkta och hänsynstagande lösningar.
Vidare läsning
 Kyle Wiggers
Kyle Wiggers








{kind=link}
Medlemsdiskussion